Introduction
Real-time object detection is becoming a cornerstone of modern intelligent systems—from autonomous vehicles and security surveillance to retail analytics and industrial automation. The need for systems that can “see” and respond instantly is no longer optional—it’s essential. At the heart of this evolution lies computer vision, powered by machine learning and deep learning techniques, especially neural networks.
Among the most effective tools in this domain is the YOLO (You Only Look Once) family of models, known for their balance of inference speed and accuracy. This article highlights how YOLO is powering real-time object detection across various domains, along with insights from a practical case study.
Business Challenge
As industries evolve toward automation, intelligence, and operational efficiency, the inability to process and respond to visual data in real time has become a critical bottleneck. Traditional computer vision systems often rely on:
- High-latency batch processing
- Manual image or video review
- Complex multi-stage detection pipelines
- Inflexible architectures not suitable for real-time environments
These limitations lead to:
| Problem Area | Impact |
| Delayed Decisions | Real-time alerts, safety mechanisms, or analytics become ineffective |
| Operational Overhead | Human monitoring required for routine visual tasks |
| Scalability Issues | Systems fail under high-load environments (e.g., multi-camera setups) |
| Missed Events | Fast-moving or transient objects go undetected |
| Low Adaptability | Hard to deploy across different edge/cloud setups |
Core Question:
How can we automate visual recognition using real-time object detection to enable faster, more accurate decisions — across various real-world scenarios — without requiring massive infrastructure or manual intervention?
Our Approach
To solve the real-time visual detection bottleneck, we developed a streamlined object detection system powered by the YOLO model, custom-trained for high accuracy and low-latency response using advanced deep learning techniques and optimized computer vision workflows.
Key Steps in Our Implementation:
Model Training
We trained the YOLO model using 10,000+ labeled open-source images, forming a robust dataset that covers a wide range of predefined object classes. The dataset included varied lighting, orientation, and background conditions to ensure the model’s effectiveness in real-world environments. This approach leveraged the power of neural networks and advanced machine learning algorithms.
GPU Acceleration
The model was trained on GPU-powered engines, significantly reducing training time and boosting inference speed. GPU acceleration allowed the system to process a high volume of data with minimal inference latency while maintaining real-time object detection performance.
Bounding Boxes and Class Mapping
YOLO detects multiple objects using bounding boxes with class labels. We predefined class mappings for consistency (e.g., person, vehicle, bag, mobile). The bounding boxes provided localized detection, which proved crucial for interpreting scenes in surveillance feeds and other dynamic visual environments.
Robust Tracking Across Input Types
Once trained, the model processed static images and video streams with impressive real-time accuracy. It was tested on:
- Image uploads
- Live and recorded videos
- CCTV surveillance feeds
The system maintained frame rates of over 55 FPS and achieved smooth tracking even under challenging lighting or high-motion conditions, ideal for edge devices.
What is YOLO?
YOLO (You Only Look Once) is a cutting-edge real-time object detection algorithm that revolutionized how machines “see” and understand visual content. Unlike traditional object detectors that scan an image multiple times, YOLO processes the entire image in a single pass, making it incredibly fast and efficient.
How YOLO Works Simplified
Instead of using a region proposal network (like older models such as R-CNN), YOLO treats object detection as a regression problem:
- It divides the image into a grid.
- Each grid cell predicts bounding boxes and class probabilities.
- The algorithm then combines predictions to detect and classify multiple objects in one go.
In our implementation, we used YOLOv5 for its sweet spot between performance, simplicity, and training efficiency.
Why We Chose YOLO
- Real-time speed for processing videos and streams.
- High accuracy in diverse environments (day/night, motion/static).
- Easy retraining on custom datasets.
- Low footprint, deployable even on edge devices.
Papers
- YOLOv1: You Only Look Once: Unified, Real-Time Object Detection
Link: https://arxiv.org/abs/1506.02640 (Joseph Redmon) - YOLOv4: Optimal Speed and Accuracy of Object Detection
Link: https://arxiv.org/abs/2004.10934 (Alexey Bochkovskiy et al.)
Result
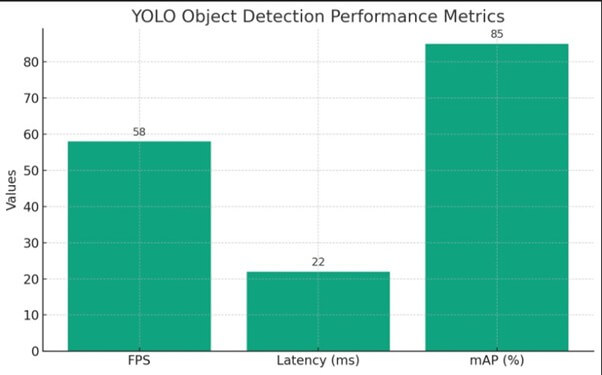
We evaluated the performance of our YOLO-based real-time object detection system across different scenarios, including CCTV surveillance feeds, video streams, and static images. Below is a summary of key performance metrics:
| Metric | Value |
| Frame Rate (GPU) | 55–60 FPS |
| Inference Latency | ~20–25 ms/frame |
| Mean Average Precision | ~85% (across trained classes) |
| Deployment Footprint | Lightweight (edge-compatible) |
| Number of Objects/Frame | 5–15 (multi-object support) |
Performance Highlights:
- 58 FPS for real-time object detection
- 22 ms inference latency per frame
- 85% mAP — high detection accuracy using machine learning models
This implementation underscores the power of combining computer vision, deep learning, and GPU acceleration for real-time object detection. With efficient model training, robust datasets, low inference latency, and high frame rates, this solution is scalable, efficient, and ready for real-world deployment on edge devices.