

LLM COUNCIL
INTRODUCTION
Large Language Models (LLM) are increasingly used to solve complex problems, ranging from code generation and technical explanations to decision support and content creation. However, no single model consistently performs best across all tasks. Each LLM has its own strengths, limitations, reasoning style, and failure modes.
LLM Council introduces a collaborative approach where multiple LLMs respond independently to a query, review each other’s outputs, and collectively synthesize a final answer. By encouraging diversity of thought and structured evaluation, this approach aims to improve accuracy, depth, and reliability in AI-generated responses. The concept, often discussed under llm council andrej karpathy, reflects a broader shift toward collaborative intelligence and structured Agentic Workflows in modern AI systems.
PROBLEM STATEMENTS
Although Large Language Models have demonstrated impressive capabilities across a wide range of tasks, their effectiveness is often constrained when used in isolation. A single LLM can generate confident yet incorrect responses, miss critical edge cases, or exhibit biased reasoning depending on the prompt and surrounding context. These shortcomings become increasingly evident in complex or high-stakes scenarios where accuracy, consistency, and reliability are essential.
As AI systems scale across organizations, manually reviewing and validating every response becomes impractical and inefficient. This highlights the need for an automated approach that enhances reliability while remaining flexible across different models. Approaches such as multi agent orchestration and evaluation patterns like llm as a judge have emerged to address these challenges by allowing models to review and improve each other’s reasoning.
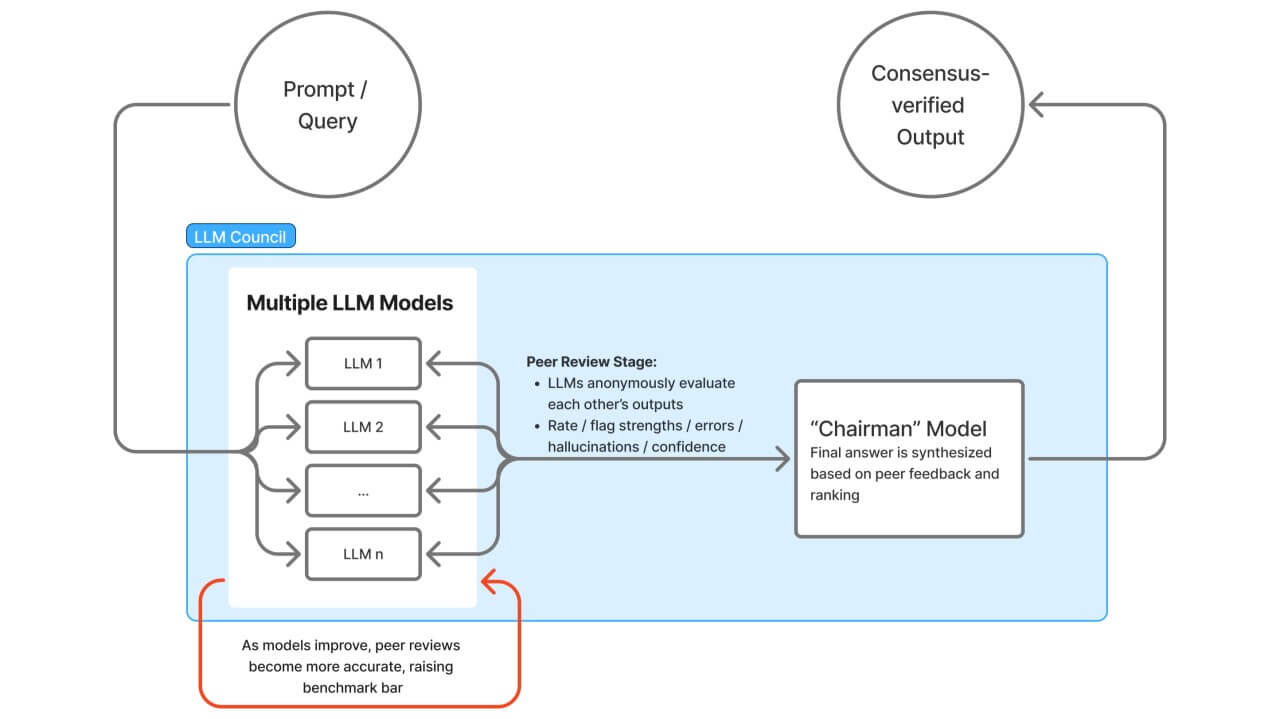
HOW LLM COUNCIL WORKS
LLM Council, specifically the open-source project introduced by Andrej Karpathy in late 2025, works by turning multiple large language models into a collaborative team that answers queries through three main stages. The llm council andrej karpathy approach represents a structured example of Agentic Workflows, where multiple AI agents contribute to a shared outcome through defined roles.
1. First Opinions (Independent Generation)
In the first stage, the user query is sent to multiple LLMs in parallel. Each model generates its response independently, without access to the outputs of other models. This isolation ensures unbiased reasoning and allows each model to apply its unique strengths, knowledge, and interpretation of the problem.
The result is a diverse set of initial responses that capture different perspectives, reasoning styles, and levels of detail. This independent generation stage forms the foundation of effective multi agent orchestration, ensuring that diversity of reasoning exists before evaluation begins.
2. Review & Ranking (Anonymous Peer Evaluation)
Once the initial responses are collected, the models enter a peer-review phase. Each LLM reviews the responses generated by other models, typically in an anonymized manner to avoid preference bias. During this stage, models evaluate responses based on factors such as accuracy, clarity, completeness, and logical consistency.
This phase closely resembles the concept of llm as a judge, where models act as evaluators rather than generators. The evaluations are then aggregated to rank the responses, helping surface the strongest and most reliable answers while identifying weaker or inconsistent ones. This review mechanism is a key component in modern Agentic Workflows, improving reliability without requiring human intervention.
3. Final Synthesis (Chairman Consolidation)
In the final stage, a designated model—often referred to as the Chairman—takes the ranked responses along with the review feedback and synthesizes them into a single, cohesive answer. Rather than selecting one response verbatim, the Chair model integrates the best insights, resolves contradictions, and fills gaps to produce a balanced and refined final output that reflects the collective reasoning of the council.
This final synthesis step demonstrates how multi agent orchestration can move beyond simple aggregation and instead produce a unified response informed by multiple reasoning paths.
LLM COUNCIL WORKFLOW
The overall workflow reflects a structured collaborative system where generation, evaluation, and synthesis operate together. Many developers exploring the LLM Council GitHub implementation view this workflow as an early practical example of scalable AI collaboration within agent-based systems.
RESULTS
In practice, applying the LLM Council workflow leads to noticeable improvements in response quality when compared to single-model outputs. The final synthesized answers tend to be more comprehensive, logically consistent, and balanced, as they are informed by multiple independent reasoning paths rather than a single perspective.
The peer-review and ranking stage helps surface stronger arguments while filtering out incomplete or weaker responses. As a result, the final output often demonstrates improved clarity and reduced hallucinations, particularly for complex or ambiguous queries. Overall, the system produces responses that are better suited for high-impact or decision-support use cases, especially in environments where llm as a judge evaluation patterns help maintain consistency.
OBSERVATIONS
Several interesting patterns emerge when working with LLM Council. Different models consistently excel at different aspects of the same problem—for example, one model may provide precise technical details, while another offers clearer explanations or identifies edge cases. The review stage frequently highlights subtle errors or assumptions that would otherwise go unnoticed in a single-model setup.
Another key observation is that model rankings vary significantly across queries, reinforcing the idea that no single LLM performs best universally. The final synthesis benefits most when rankings are treated as contextual signals rather than absolute judgments. This confirms that collaborative reasoning, enabled through multi agent orchestration and structured Agentic Workflows, is more effective than relying on any individual model in isolation.
So when to use LLM Council
Using the LLM Council for every single prediction is generally inefficient due to high latency and cost.
- Low-risk tasks: (e.g., summarizing a short, simple email, simple weather queries) One model is enough.
- High-risk/Complex tasks: (e.g., legal contract analysis, medical insights, complex coding, architectural decisions) The LLM Council is recommended because it uses multiple models and structured evaluation approaches similar to llm as a judge, significantly reducing the error rate and, in turn, the cost of errors.
CONCLUSION
LLM Council shows that collaborative reasoning beats single-model intelligence for complex, high-risk tasks. By combining independent thinking, peer review, and structured synthesis, it significantly improves accuracy, depth, and reliability—making it ideal when the cost of errors is higher than the cost of extra inference. The llm council andrej karpathy approach also highlights how future AI systems will increasingly rely on coordinated models, multi agent orchestration, and structured Agentic Workflows, while single models remain sufficient for low-risk, simple use cases.
REFERENCES
Andrej Karpathy. LLM Council
GitHub Repository: LLM Council GitHub



22 comments on “From Solo Models to Collective Intelligence: Introducing LLM Council”